由於朋友工作關係,常常需要蒐集各部落客,部落格的名稱,部落客的網址,和主人的email蒐集起來,並且詳列出來後,它可以輕易地一鍵copy,這樣可以省得它每次都要用各自官方的部落格去搜尋相關資料,然後再將這些資料手動貼上。
看了看這題目,我覺得我應該辦得到! 所以現在就著手來嘗試吧!
第一步:是否有API
這是我想到的第一件事,所以立刻來實驗,以痞客幫為案例,
我立刻搜尋到他們有提供相關API使用,PIXNET api
然後立刻發現他們有讀取使用者公開資訊! 在這
立刻來嘗試一下
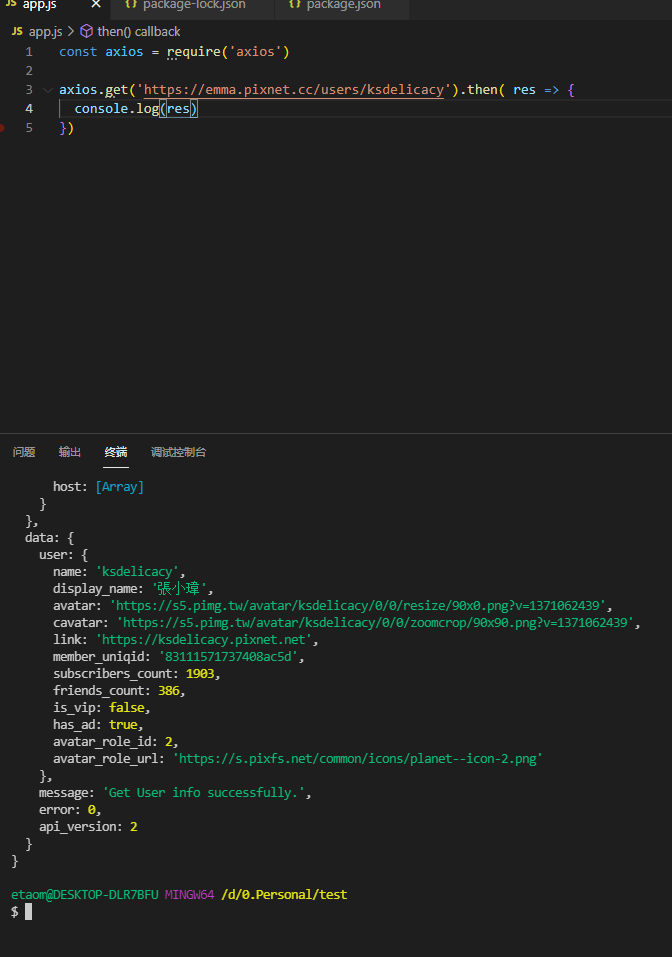
立刻得到了有關使用者名稱以及部落客網址
第二步:問題:不知道作者的ID
因為朋友起初的希望是能透過引擎搜尋模糊搜尋,也許是輸入中文名,也許是輸入部落格名,然後直接列出相關作者的帳號,部落格名稱,網址,
這我遇到的第一個問題,API沒有提供模糊查詢作者並列出相關資料的清單功能,
所以我換了個想法,是否可以置入GOOGLE的搜尋引擎,輸入關鍵字尋找,並對痞客邦裡的相關資訊進行搜尋,並列出相關部落格,最後讓我來抓取頁面上的資訊。
不管怎樣,先來想辦法放入引擎
置入Google引擎
後來我找到Google有提供自訂搜尋引擎,可以只針對某些網址進行搜尋
Google Programmable Search
順利放進去了,但我發現我無法順利地使用JS來抓取到Google 所產生的新元素…搞了半天…(崩潰)
所以我開始嘗試研究,最後發現是網頁生成順序的問題,當瀏覽器在載入網頁時,瀏覽器會先分析這個 HTML 檔案且「由上而下」依序來讀取解析網頁的內容:
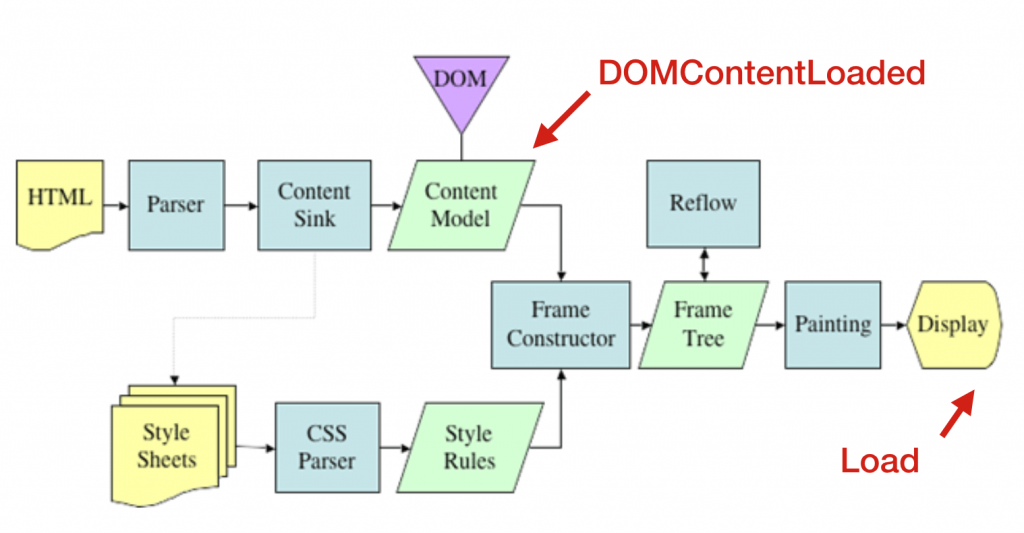
會發現DOM的形成是在Content Model成行時才出現,所以像google這種工具原件,會在Script讀取完,網頁通通跑完在最後渲染的時候才會出現HTML的元素標籤。
所以當我載入我的JS的時候,DOM都還沒形成,根本就抓不到。
因此這個時候就必須要利用 DOMContentLoaded 或 load 事件,來確保 DOM 結構被完整的讀取跟解析。
1 | document.addEventListener("DOMContentLoaded", function(){ |
或是
1 | window.addEventListener("load", function(event) { |
兩者的差異在load 事件是在網頁「所有」資源都已經載入且畫面渲染完成後才會觸發,
而 DOMContentLoaded 事件是在 DOM 結構被完整的讀取跟解析後就會被觸發,不須等待外部資源讀取完成。
如上圖,load 事件是會在 DOMContentLoaded 之後才被觸發,這兩個事件都可以確保網頁結構的載入完成。
後來我嘗試使用DOMContentLoaded事件,但發現還是無法選到,我想是因為此時google的外部資源尚未讀取完成,所以還抓不到,
所以又改成load事件來嘗試,最後終於成功
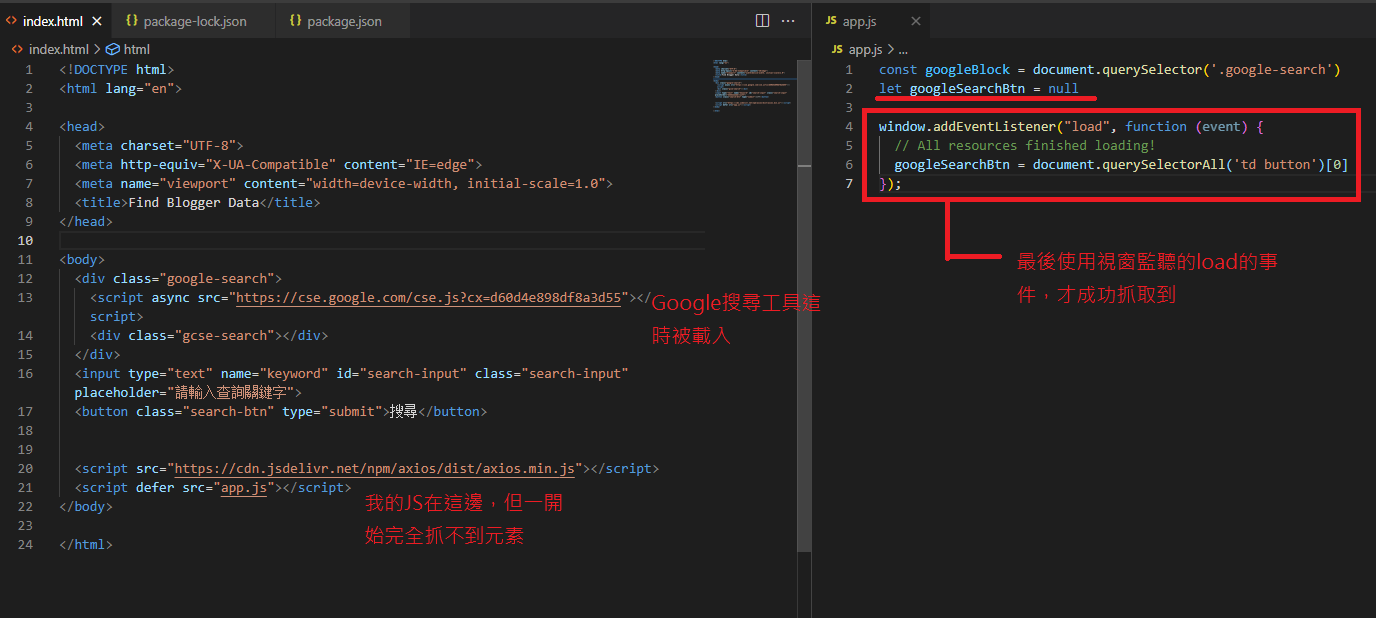
過程當中也嘗試過一些元素標籤屬性defer,async,這些用法,但都不管用,他們的用法說明可以看這裡
網頁效能優化之非同步載入js檔案
現在可以操控到手的資料啦!!
選到GOOGLE的搜尋按鈕後,就可以在上面下監聽器了,
每段程式碼都附上備註說明
1 | window.addEventListener("load", function (event) { |
接著就是版面排一排,把該置入的資料丟進去,最後設定一個複製按鈕
作法是先所有按鈕選出,接著按鈕身上手動設定了dataset的id,所以當點擊按鈕可以取得id,將id可以用來選擇所有按鈕的index,
接著對元素使用element.select()
再使用 navigator.clipboard.writeText()來指定要複製到剪貼簿上,
成功跳通知,也可以不跳
1 | dataPanel.addEventListener('click', (e) => { |

大功告成!